
Sommario :
Cluster di computers: definizione.
Il calcolo distribuito su Cluster di PC.
La necessita` aguzza l'ingegno !
I sistemi operativi multitasking e i processori multicore .
XTraceCluster: ray-tracing su cluster di PC per applicazioni di Virtual Reality.
Ulteriori letture e approfondimenti.
Cluster di computers : definizione.
Un Cluster di Computers e` un insieme di comuni* PC collegati in rete che, assieme, concorrono alla risoluzione numerica di un problema computazionalmente complesso e/o tempo-consumante.
[ * comune e` qui usato nella accezione di "facilmente reperibile" ovvero basantesi su tecnologie commercialemnte diffuse e, quindi, a basso costo ].
Il calcolo distribuito su Cluster di PC.
In molte applicazioni informatiche, specialmente quelle real-time, e` necessario disporre di notevoli potenze di calcolo.
Applicazioni di Realta` Virtuale, simulatori di volo, analisi FEA, esperimenti di fisica atomica [CERN], data mining, indagini meteorologiche, DSP, image processing ... possono mettere in crisi anche i processori piu` potenti.
Fino agli anni '80 l'unico modo per poter affrontare problemi computazionalmente complessi e/o tempo-consumanti era quello di affidarsi alla esuberante potenza di calcolo dei supercomputer : aziende del calibro di IBM, SUN, DEC, SGI, HP, Compaq erano (e molte lo sono tuttora) leader nella realizzazione di sistemi di calcolo davvero performanti.
Quello dell'uso dei supercomputer e` pero` un approccio che presenta un grosso inconveniente : e` molto costoso !
La necessita` aguzza l'ingegno !
Gli alti costi di un supercomputer (tipicamente dell'ordine dei milioni di euro) non consentono ai piccoli centri di ricerca o alle piccole Universita` di poterne acquistare uno per uso personale .
Per alcune classi di problemi, in particolar modo quelle che si prestano ad un approccio del tipo divide et impera da tempo e` stata escogitata una soluzione ugualmente efficiente ma decisamente molto meno costosa: il calcolo distribuito su PC collegati in rete.
L'idea di utilizzare grappoli (clusters) di computer per raggiungere potenze di calcolo inaudite risale agli albori dell'informatica, tuttavia la prima realizzazione di un cluster funzionante su dei comuni PC si deve al ricercatore Donald J. Becker che, nel 1994, assemblo` un set di 16 Intel 80486DX collegati da una rete Ethernet da 10 Megabit.
Questo fu il risultato di uno dei progetti della NASA tesi a realizzare sistemi di calcolo molto potenti ma, al contempo, poco costosi: il progetto Beowulf .
I sistemi operativi multitasking e i processori multicore
La creazione del primo cluster di PC fu possibile solo grazie al fatto che proprio in quegli anni si andava diffondendo il sistema operativo Linux, una variante di Unix rilasciata sin da subito in modalita` open source (in pratica gratuito!) e funzionante su processori di fascia bassa come gli Intel 80486.
Il sistema operativo Linux gia` all'epoca disponeva degli ingredienti necessari allo scopo :
- Stabilita` : una applicazione scritta male non blocca l'intero sistema.
- Multitasking : si possono eseguire piu` applicazioni contemporaneamente.
- MultiThreading reale di tipo pre-emptive : ciascuna applicazione puo` avviare piu` percorsi (thread) di esecuzione per ottimizzare di tempi delle elaborazioni.
- Capacita`di Networking : piu` macchine possono condividere risosorse di calcolo e di data-storage.
Per quanto riguarda l'hardware i moderni processori multi-core come ad esempio i Pentium QuadCore di Intel consentono di sfruttare appieno le capacita` multitasking/multithreading di Unix/Linux e dei sistemi operativi di casa MicroSoft Wndows XP e Vista.
Infine una riferimento sui costi: sono sufficienti quattro Pentium QuadCore (costo complessivo: meno di 10000 dollari) per eguagliare la potenza di calcolo di Deep-Blue, il supercomputer di IBM (costo: circa 10 milioni di dollari) che, a meta` degli anni '90, batte` a scacchi l'allora campione del mondo Kasparov!
XTraceCluster: ray-tracing su cluster di PC per applicazioni di Virtual Reality.
Avendo avuto la necessita` di incrementare la potenza di calcolo del mio computer per alcune applicazioni inerenti il ray-tracing e l'auralizzazione ho deciso di ... costruirmi il mio personal-cluster alla Beowulf!
Pur nella sua semplicita` esso ha dato prova di notevole efficienza e mi ha consentito di toccare con mano i vantaggi del calcolo distribuito : elevata potenza a bassi costi !
L'applicazione XTrace e` una applicazione di rendering grafico basantesi su tecniche di ray-tracing che, inizialmente, e` stata sviluppata in versione mono-processore .
Sin da subito pero`, non appena gli scenarii da renderizzare diventavano un poco piu` complessi, essa mi metteva in ginocchio anche il Pentium piu` veloce !
Che soluzione potevo adottare per ottenere un rendering di tipo ray-traced in real-time a costi contenuti confrontabili con le mie (perennemente) scarse risorse finanziarie ?
Ecco allora che dopo molte ...molte ... ma moooolte nottate insonni ... ha finalmente visto la luce la variante clustered di XTrace: XTrace-Cluster (che fantasia!) .
XTraceCluster funziona sotto Windows XP ed e` costituito da tre componenti: uno scheduler , XTraceCluster.exe, e due applicazioni satelliti, XTraceSatellite_Socket.exe e XTraceSatellite_HTTP.exe.
Le tre applicazioni e il file sorgente dello scheduler sono nelle directory Contribs\bin e Contribs\sources di questo CD.
Lo scheduler e` l'applicazione principale che serve per organizzare e riordinare l'esecuzione dei diversi tasks eseguiti dai satelliti sui diversi nodi (host) del cluster.
La connessione di rete puo` sfruttare due modalita` :
- HTTP, fa uso del protocollo HTTP ed e` la modalita` consigliabile laddove siano installati sistemi di protezione antivirus e/o firewall.
- Socket, fa uso dello stack raw TCP/IP piu`a basso livello rispetto al precedente ed e`, pertanto, piu` veloce. Tuttavia richiede una piu` attenta configurazione dei firewall e/o antivirus per poter funzionare correttamente.
Per poter subito sperimentare il funzionamento di XTraceCluster il mio consiglio e` di utilizzare la versione HTTP del satellite .
C'e` poi una terza modalita` Thread che consente di sfruttare la presenza di processori multi-core , come il Pentium Dual/Quad Core o anche i piu` datati Pentium 4 HT (Hyper-Threaded).
Se necessario si possono utilizzare contemporaneamente tutte e tre le modalita` operative : Thread, Socket e HTTP.
La figura seguente illustra come nello scheduler si possano utilizzare contemporaneamente tutte e tre le modalita`: per prova si possono avviare le applicazioni satellite XTraceSatellite_Socket.exe e XTraceSatellite_HTTP.exe sulla stessa macchina su cui e` avviata l'applicazione scheduler XTraceCluster.exe, usando lo speciale indirizzo IP di loop-back 127.0.0.1 .
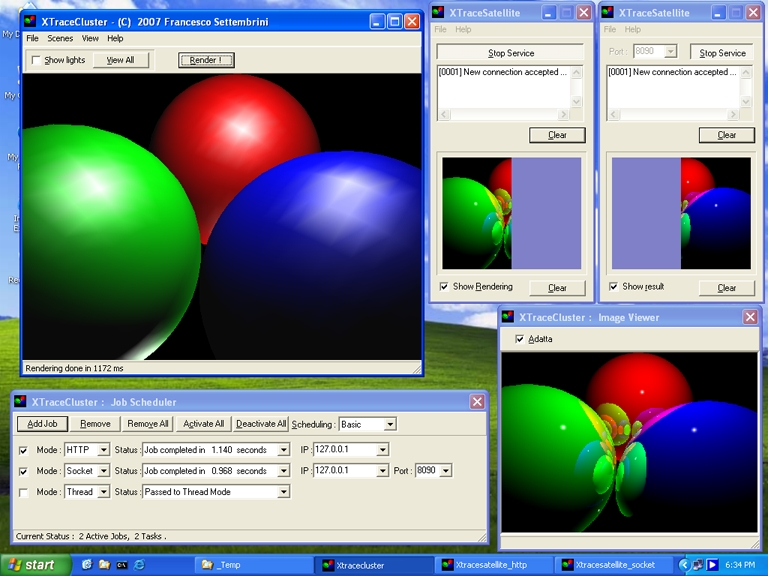
Come si puo` notare ciascun job (le due applicazioni satellite in alto a destra) renderizza solo meta` dell'intera area : se queste applicazioni satellite fossero eseguite su nodi distinti del cluster esse verrebbero renderizzate parallelamente (cioe`contemporaneamente), dimezzando cosi` i tempi di calcolo. Ovviamente se le applicazioni satellite fossero quattro i tempi di rendering diverrebbero un quarto, e cosi` via : piu` nodi di calcolo sono presenti e maggiore sara` la potenza di elaborazione del cluster (tipica proprieta` di potenza scalare di un cluster di computers).
Questi rendering parziali prodotti da ciascun job verranno poi ricomposti dallo scheduler per produrre l'immagine finale complessiva, come si puo` notare in basso a destra della figura precedente.
Per curiosita` riporto anche, nella figura seguente, il risultato dell'elaborazione con tutti e tre i job attivati: HTTP, Socket e Thread.
Potete notare che il tempo complessivo e` di 1234 millisecondi contro i 1172 millisecondi del rendering precedente : questo perche` tutti e tre i task sono eseguiti sulla stessa macchina che, non disponendo di un processore multi-core, risulta impropriamente sovraccaricata di lavoro (overhead).
Se invece si eseguono i due task satellite su nodi distinti dal nodo del task thread il tempo complessivo di elaborazione si ridurra` significativamente.

Vediamo ora qualche esempio piu` impegnativo.
Dal menu` Scenes dell'applicazione principale XTraceCluster.exe si possono selezionare scenarii piu complessi del precedente: consideriamo ad esempio il rendering di 364 sfere.
Inoltre, questa volta, colleghiamo tra loro ben dieci calcolatori ( nell'esempio ho fatto uso degli elaboratori presenti al piano terra del mio dipartimento ) piu` un undicesimo sui cui viene eseguito lo scheduler.
Lo scheduler supporta tre tipi differenti di scheduling :
- Basic : e` lo scheduling piu` elementare e anche il meno efficiente. Esso suddivide l'intero lavoro da fare per quanti sono gli host del cluster. Questa suddivisione puo` andar bene se tutti i nodi della rete sono costituiti da processori di ugual potenza: se invece il cluster e` costituito da nodi eterogenei ( nel mio dipartimento coesistono Pentium III e Pentium 4 di diverse generazioni e velocita` ...) questo tipo di scheduling e` svantaggioso perche` introduce dei tempi di inutilizzo dei processori. I processori veloci termineranno prima il loro task e, in seguito, resteranno in attesa fino a che non abbia terminato anche il processore piu` lento.
- Granular : e` il tipo di scheduling che, sul campo, ha dato i risultati migliori. Esso suddivide l'intero lavoro in un numero di task pari non al numero di nodi del cluster ma pari, invece, ad un numero multiplo dei nodi. Granularizzando opportunamente il lavoro si riducono i tempi morti : ogni volta che un nodo termina il suo task lo scheduler gliene assegna un altro fino a che tutti i task non saranno terminati. Se si eccede troppo nella granularizzazione e si opera su una rete lenta si rischia di peggiorare il rendimento finale perche` si introduce un overhead causato dall'eccessivo traffico di rete.
- Balanced : e` simile alla Basic solo che, previo test di velocita`, ad ogni nodo viene assegnato un task commisurato alla sua potenza. In pratica anziche` suddividere l'intera area da renderizzare in slices uguali (come fa la versione Basic) essa viene suddivisa in slices rettangolari con larghezza proporzionale alla velocita` di calcolo di ciascun nodo : a computer piu` veloce viene assegnata area maggiore, e viceversa. Vorrei far notare che data la natura non strettamente predittiva del ray-tracing questa tecnica, contrariamente alle aspettative, non ha dato buoni risultati.
In definitiva la miglior modalita` di scheduling si e` dimostrata essere quella di tipo Granular.
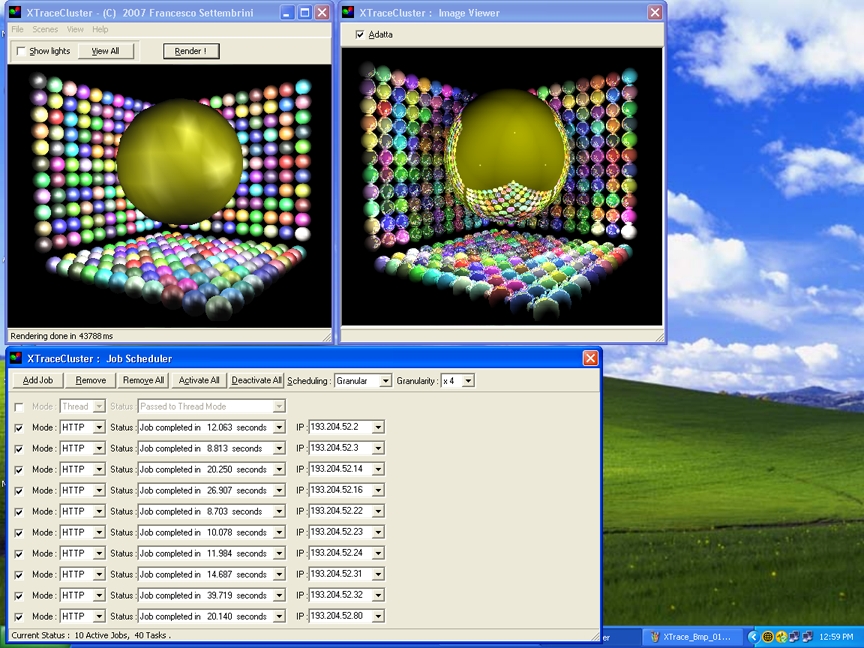
Il rendering su 10 nodi di calcolo e` stato eseguito in circa 44 secondi mentre lo stesso lavoro su una singola macchina aveva richiesto ben 380 secondi : un incremento di prestazioni di piu` dell' 850 % !!
Sinceramente ritengo che, come prima esperienza nel campo del calcolo parallelo, i risultati siano piu` che incoraggianti !!!
Senza considerare che il tutto e` ulteriormente migliorabile se si usa una connessione di rete piu` efficiente (ad esempio una Gigabit Ethernet contro la 10 Mb usata nelle prove) e se si sotituiscono gli hub con i piu` efficienti switch.
Vi lascio immaginare che potenze di calcolo si potrebbero ottenere se, al posto dei 10 computer piuttosto obsoleti della prova, si utilizzassero 10 server Xeon QuadCore da 3 Ghz in configurazione a doppio processore !
Ulteriori letture e approfondimenti.
Per i piu` curiosi riporto infine un paio di letture storiche sulla realizzazione dei cluster di tipo Beowulf.
MediaMente approfondimento del 8 aprile 1998
The Stone SouperComputer - ORNL's First Beowulf-Style Parallel Computer
By: Francesco Settembrini - Dicembre 2007 - f.settembrini@poliba.it - www.dft.poliba.it